Virtual method enables screening of billions of chemical compounds
Posted: 10 January 2022 | Victoria Rees (Drug Target Review) | No comments yet
A new platform, named Virtual Synthon Hierarchical Enumeration Screening, has been developed by researchers to efficiently discover drugs.

Researchers at the University of Southern California (USC) Dornsife College of Letters, Arts and Sciences, US, have created a screening process that increases the chances of finding effective drugs in a fraction of the time and at significantly less expense than current methods of drug discovery.
The new method, dubbed Virtual Synthon Hierarchical Enumeration Screening (V-SYNTHES), requires a fraction of the time and computing resources compared to other algorithms for virtual screening of “readily available for synthesis” compound (REAL Space) libraries. Instead of screening billions of fully pre-built molecules, V-SYNTHES starts by sifting through the much smaller library of synthons to find those that fit some part of the protein’s target pocket.
Synthons with a good match in one part of the pocket are then “clicked” together with other synthons that may fit the other part. Repeating this process by adding pieces allows the researchers to build complete molecules and check their fit in the target pocket step by step, greatly facilitating the search for effective drugs.
Biomarkers are redefining how precision therapies are discovered, validated and delivered.
This exclusive expert-led report reveals how leading teams are using biomarker science to drive faster insights, cleaner data and more targeted treatments – from discovery to diagnostics.
Inside the report:
- How leading organisations are reshaping strategy with biomarker-led approaches
- Better tools for real-time decision-making – turning complex data into faster insights
- Global standardisation and assay sensitivity – what it takes to scale across networks
Discover how biomarker science is addressing the biggest hurdles in drug discovery, translational research and precision medicine – access your free copy today
To test V-SYNTHES, as outlined in the journal Nature, the researchers first focused on cannabinoid receptors, found throughout the body. Cannabinoid receptors are known for mediating the effects of marijuana, but they also are key targets for pain relief and diseases such as cancer, multiple sclerosis and Alzheimer’s and Parkinson’s diseases.
Searching through synthon libraries, the team found that V-SYNTHES was more than 5,000 times faster than standard algorithms at finding drug-like molecules that could selectively target cannabinoid receptors. Furthermore, when the predicted drug candidates were synthesised and then tested in the lab, the number that actually worked – meaning those that effectively bound and blocked the cannabinoid receptors – was twice that of the candidates suggested by standard search algorithms.
Repeating the search to find other molecules that were similar to their first round of best hits, the lab identified even more potent molecules that may work in clinical settings.
“V-SYNTHES doubled our success rate and helped to find very potent drug candidates with clinically relevant binding affinities,” said lead researcher Associate Professor Vsevolod Katritch.
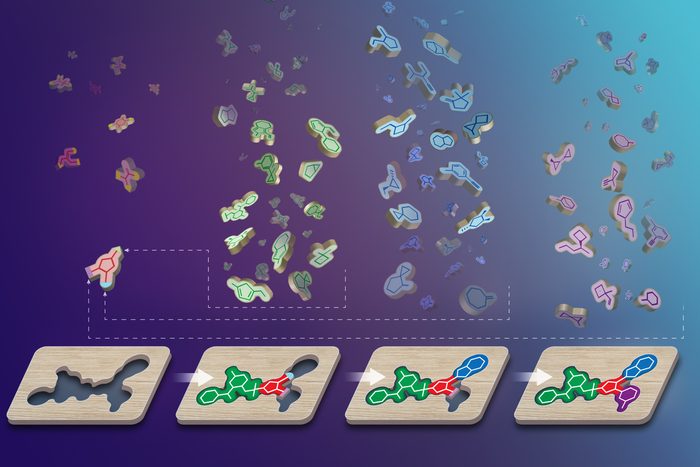
Chemists can build effective drugs using chemical components called synthons, represented by the colourful puzzle pieces, that match the shape of a therapeutic target on a protein, represented by the wooden block [credit: USC Dornsife/Yekaterina Kadyshevskaya].
The researchers note that the algorithm should work for any target protein with a well-characterised three-dimensional (3D) structure that it can analyse and match to synthon combinations. While the current study uses V-SYNTHES to screen 11 billion molecules, the team also say that theoretically it can be scaled up many more orders of magnitude.
Furthermore, the cost of screening using standard methods multiplies every time another synthon joins the mix. The cost of V-SYNTHES, in contrast, increases much more slowly, by a fixed amount for each additional synthon.
However, there is room for improvement. While the process of using V-SYNTHES currently requires substantial human attention, the team is now working to upgrade V-SYNTHES to fully automate the process. The group also aims to use V-SYNTHES to screen for drug candidates targeting other proteins that are involved with a variety of intractable diseases.
Moreover, the researchers say that V-SYNTHES can be implemented in the biotech and pharmaceutical industries, where streamlined drug discovery can best benefit patients in need of new and better therapies.
Related topics
Cannabinoids, Drug Discovery, Drug Discovery Processes, Informatics, Medicinal Chemistry, Screening
Related conditions
Alzheimer’s disease, Cancer, Multiple Sclerosis, pain, Parkinson's disease
Related organisations
University of Southern California (USC)
Related people
Associate Professor Vsevolod Katritch